本文最后更新于 2023年10月13日 上午
说在前面 因为在Twitter看到Appare!的广播,于是想自己录制radiko的源,故使用Python分析其认证以及播放过程
认证
打开F12,一共两次认证,刚开始还以为只要一次认证就行了,重新看了一下漏了一次认证
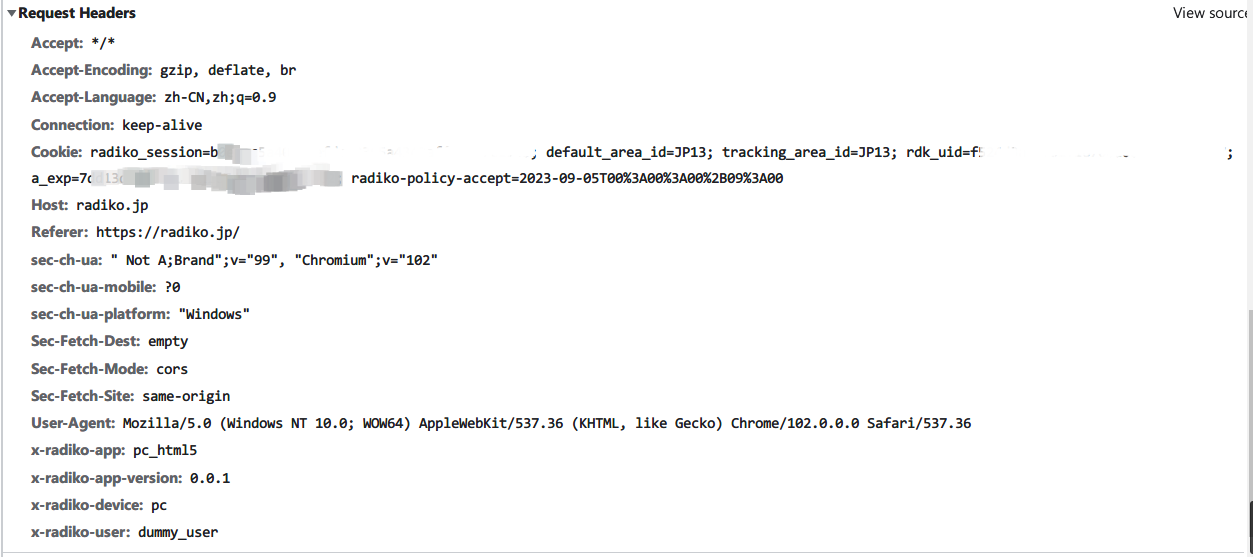
auth1
这个很简单,拼好请求头就行了
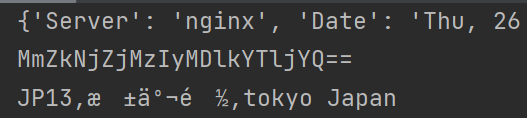
返回的响应头比较重要:
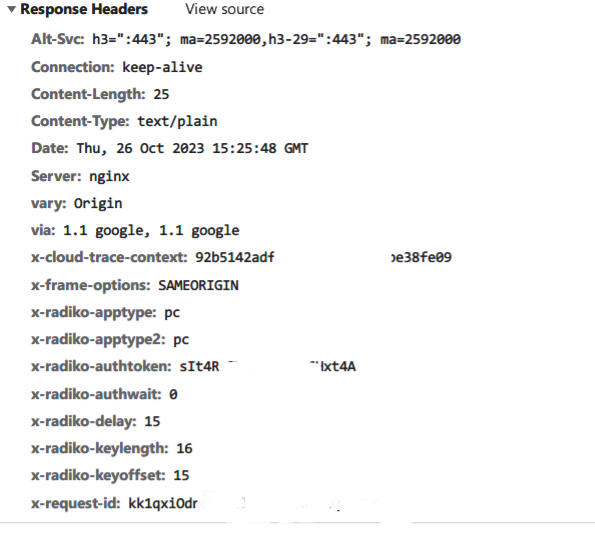
auth2 auth2应该是返回给服务器认证第一次的authtoken,使token有效(最开始只认证一次,token怎么都用不了)
先分析请求头:
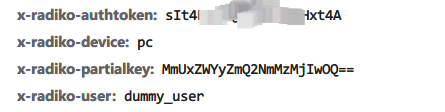
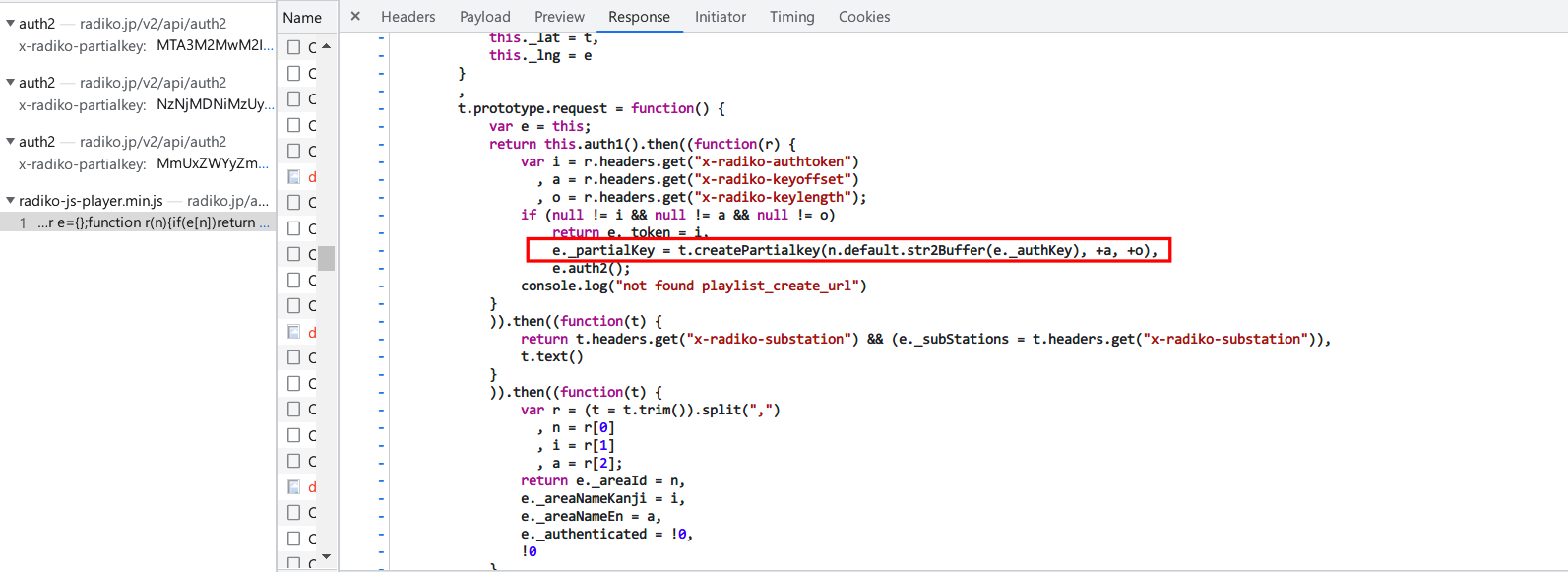
authtoken就是auth1返回的key,多了个partialkey,直接搜索这个
发现在这个js里面生成:
接下来就是分析算法了
可以看到offset和length都是上面auth1响应头上的参数
然后这个生成算法:
就是从一个字符串中偏移量的位置上截取指定长度字符串,然后Base64编码
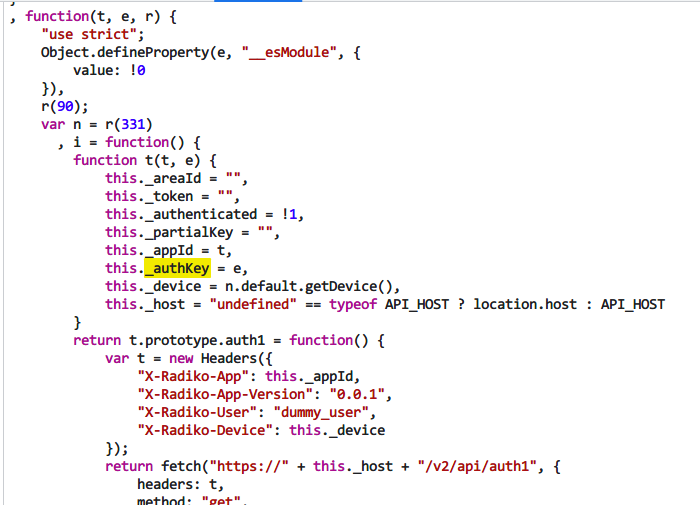
然后这个字符串是authkey(不是响应头的那个key),搜了一下:
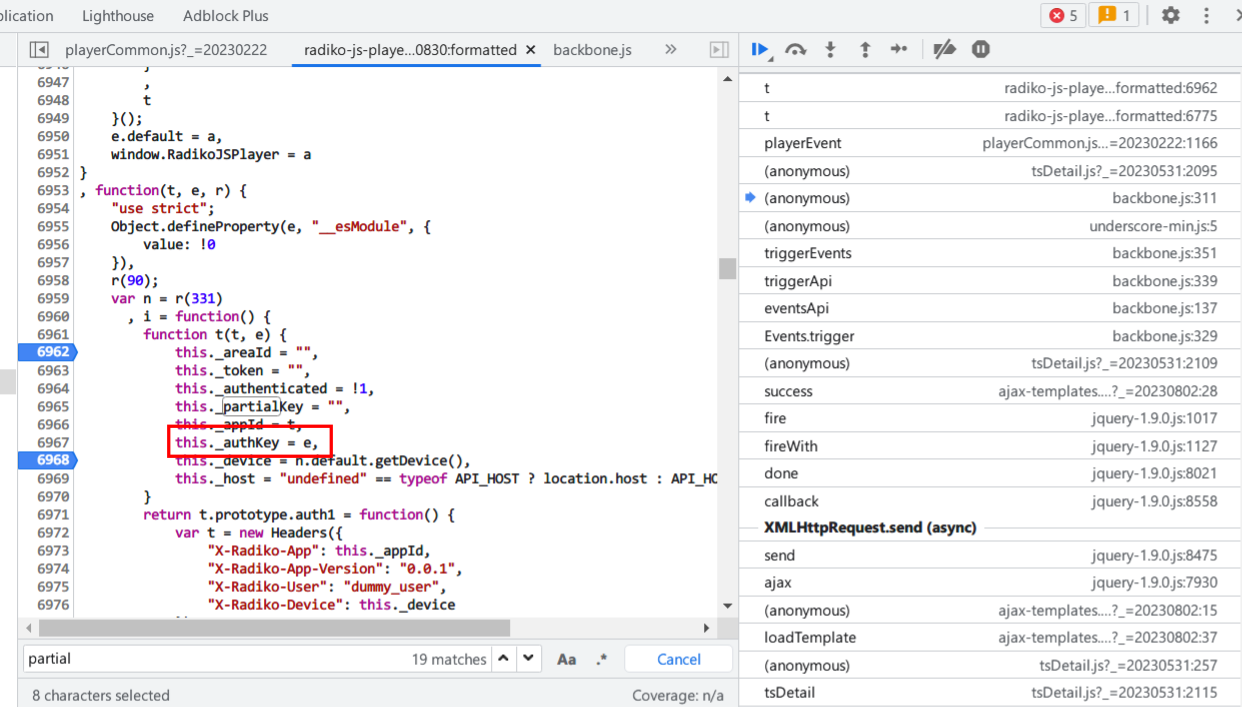
这一步直接断点调试了:
看一下调用栈:
这个authkey就是一个常量
复制好,测试一下,完全一致
1 2 3 4 5 6 7 8 9 10 import base6415 16 "bcd151073c03b352e1ef2fd66c32209da9ca0afa" 'utf-8' )print (encoded_string)
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import requestsimport base64"https://radiko.jp/v2/api/auth1" "https://radiko.jp/v2/api/auth2" "Host" : "radiko.jp" ,"Referer" : "https://radiko.jp/" ,"x-radiko-app" : "pc_html5" ,"x-radiko-app-version" : "0.0.1" ,"x-radiko-device" : "pc" ,"x-radiko-user" : "dummy_user" ,"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" "default_area_id" : "JP13" ,"tracking_area_id" : "JP13" print (response.headers)int (response.headers["x-radiko-keyoffset" ])int (response.headers["x-radiko-keylength" ])"bcd151073c03b352e1ef2fd66c32209da9ca0afa" 'utf-8' )print (encoded_string)"Host" : "radiko.jp" ,"Referer" : "https://radiko.jp/" ,"x-radiko-app" : "pc_html5" ,"x-radiko-app-version" : "0.0.1" ,"x-radiko-authtoken" : response.headers["x-radiko-authtoken" ],"x-radiko-device" : "pc" ,"x-radiko-partialkey" : encoded_string,"x-radiko-user" : "dummy_user" ,"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" print (res.text)
注意你需要日本IP,非日本IP无法认证
下载
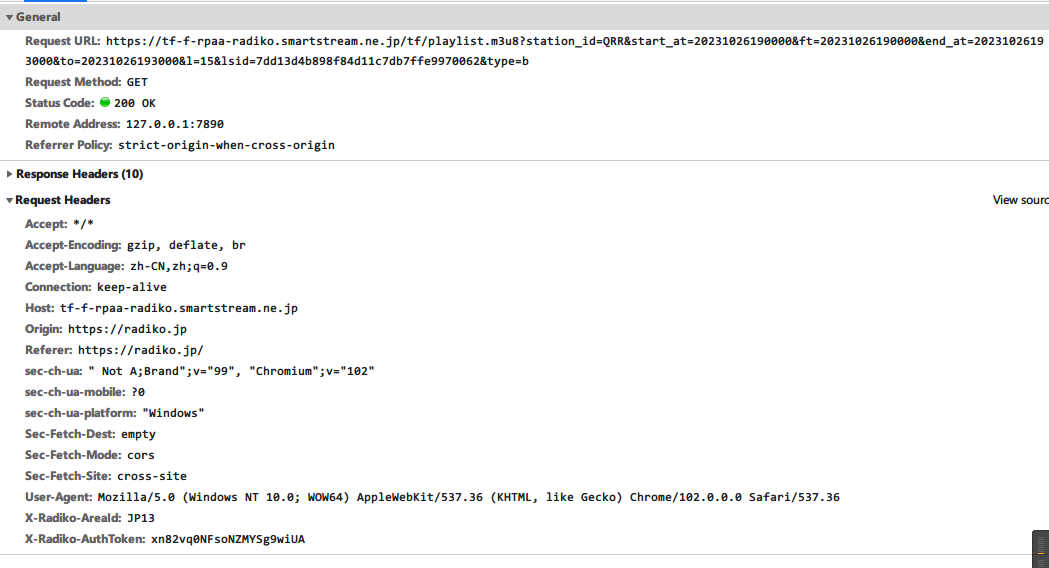
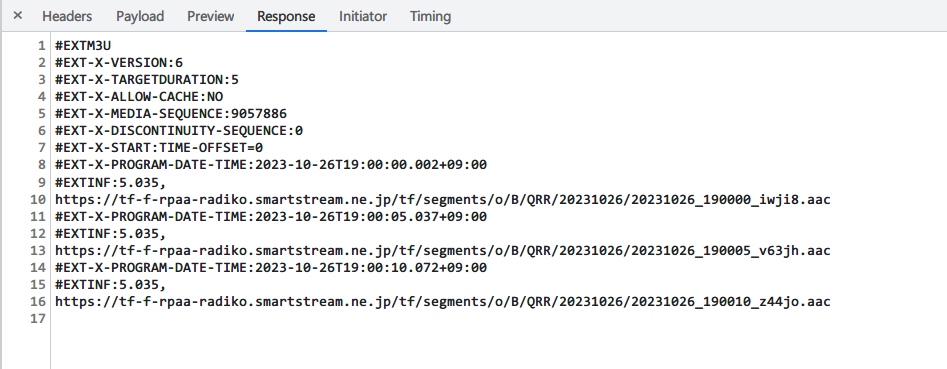
首先获取playlist,然后每隔固定时间调用playlist里的链接,获取真实文件,下载即可。
这个lsid不知道有什么用,去掉也可以
然后每隔固定时间访问这个链接,获取真实文件链接,这个链接是不会变化的,你可以存起来然后一次下载。
最后用ffmpeg拼接
获取全部文件名部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import timeimport requestsimport recompile ("https://.*?station_id=QRR" )compile ("https://.*?\.aac" )"https://tf-f-rpaa-radiko.smartstream.ne.jp/tf/playlist.m3u8?station_id=QRR&start_at=20231026190000&ft=20231026190000&end_at=20231026193000&to=20231026193000&l=15&lsid=&type=b" "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" ,"X-Radiko-AuthToken" : "8mqcBUKP9o6wKKa1TKBv5g" "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" print (data.text)0 ]set ()def get_aac_lists ():0 while count < 3 :try :"&_=" + str (int (round (time.time() * 1000 ))),2 )return audio_listsexcept requests.exceptions.RequestException:1 print ("重试中……" )while True :for i in lists:if i not in aac:with open ("aac.txt" , 'a' ) as f:"\n" )7 )
没有判断结束,可以正则获取结束时间,然后关闭
总结 算是比较简单的JS逆向(但是我好菜,中间参考了别人的文章),算是学到了一点吧。
参考:
https://koukun.jp/?p=316
https://qiita.com/taittide/items/7219cc9ff6788423ab50 (这都是3年前的文章,radiko的认证竟然一点都没改过,不愧是日本)