本文最后更新于 2022年9月15日 晚上
Rust [toc]
快速上手 新建项目 1 2 $ cargo new world_hello $ cd world_hello
运行项目
编译+运行
等价于
1 2 3 4 $ cargo buildin 0.00s
高性能:
1 2 cargo run --release
代码检查 基础入门 变量 可变性 Rust 的变量在默认情况下是不可变的
这样就会报错
需要修改为可变类型:
使用下划线开头忽略未使用的变量 如果你声明了一个变量,但是没有使用,你可以在变量名前加入下划线,忽略警告
变量解构 例子:
1 let (a, mut b): (bool ,bool ) = (true , false );
解构式赋值 例子:1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct Struct {i32 fn main () {let (a, b, c, d, e);1 , 2 );1 , 2 , 3 , 4 , 5 ];5 };assert_eq! ([1 , 2 , 1 , 4 , 5 ], [a, b, c, d, e]);
常量 声明常量:
1 const MAX_POINTS: u32 = 100_000 ;
其中,数字用下划线隔开,提高了可读性
变量遮蔽(shadowing) 可以简单理解为变量的作用域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn main () {let x = 5 ;let x = x + 1 ;let x = x * 2 ;println! ("The value of x in the inner scope is: {}" , x);println! ("The value of x is: {}" , x);in the inner scope is: 12 6
数据类型
数值类型: 有符号整数 (i8, i16, i32, i64, isize)、 无符号整数 (u8, u16, u32, u64, usize) 、浮点数 (f32, f64)、以及有理数、复数
字符串:字符串字面量和字符串切片 &str
布尔类型: true和false
字符类型: 表示单个 Unicode 字符,存储为 4 个字节
单元类型: 即 () ,其唯一的值也是 ()
数值类型 整型 默认i32
长度
有符号类型
无符号类型
8 位
i8u8
16 位
i16u16
32 位
i32u32
64 位
i64u64
128 位
i128u128
视架构而定
isizeusize
整形字面量可以用下表的形式书写:
数字字面量
示例
十进制
98_222
十六进制
0xff
八进制
0o77
二进制
0b1111_0000
字节 (仅限于 u8)
b'A'
显式处理整型溢出
使用 wrapping_* 方法在所有模式下都按照补码循环溢出规则处理,例如 wrapping_add
如果使用 checked_* 方法时发生溢出,则返回 None 值
使用 overflowing_* 方法返回该值和一个指示是否存在溢出的布尔值
使用 saturating_* 方法使值达到最小值或最大值
浮点型(IEEE754) 默认f64
避免在浮点数上测试相等性
当结果在数学上可能存在未定义时,需要格外的小心
NaN
例如:
1 2 3 4 fn main () {let x = (-42.0_f32 ).sqrt ();assert_eq! (x, x);
位运算 与其他语言一样
运算符
说明
& 位与
相同位置均为1时则为1,否则为0
| 位或
相同位置只要有1时则为1,否则为0
^ 异或
相同位置不相同则为1,相同则为0
! 位非
把位中的0和1相互取反,即0置为1,1置为0
<< 左移
所有位向左移动指定位数,右位补0
>> 右移
所有位向右移动指定位数,带符号移动(正数补0,负数补1)
序列 例子
1 2 3 4 5 6 7 8 9 10 11 12 13 for i in 1 ..=5 {println! ("{}" ,i);1 2 3 4 5 for i in 'a' ..='z' {println! ("{}" ,i);
字符、布尔、单元类型 Char 使用unicode编码,占用4字节32位
Bool 没什么好说的
单元类型: () 占位用,()不占用任何内存
语句和表达式 语句
语句,完成了一个具体的操作,但是并没有返回值
表达式
表达式会进行求值,然后返回一个值,表达式如果不返回任何值,会隐式地返回一个 ()
表达式不能包含分号 。这一点非常重要,一旦你在表达式后加上分号,它就会变成一条语句,再也不会 返回一个值
1 2 3 4 5 fn add_with_extra (x: i32 , y: i32 ) -> i32 {let x = x + 1 ; let y = y + 5 ;
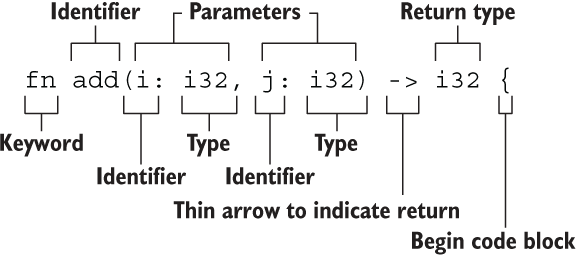
函数
Rust函数特点:
函数名和变量名使用蛇形命名法(snake case) ,例如 fn add_two() -> {}
函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
每个函数参数都需要标注类型
函数返回 函数的返回值就是函数体最后一条表达式的返回值,当然我们也可以使用 return 提前返回
1 2 3 4 5 6 7 8 9 fn plus_five (x:i32 ) -> i32 {5 fn main () {let x = plus_five (5 );println! ("The value of x is: {}" , x);
也可以同时使用:
1 2 3 4 5 6 7 fn plus_or_minus (x:i32 ) -> i32 {if x > 5 {return x - 5 5
特殊返回类型 无返回值()
函数没有返回值,那么返回一个 ()
通过 ; 结尾的表达式返回一个 ()
例如:
1 2 3 fn report <T: Debug >(item: T) {println! ("{:?}" , item);
永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverge function ),特别的,这种语法往往用做会导致程序崩溃的函数:
1 2 3 fn dead_end () -> ! {panic! ("你已经到了穷途末路,崩溃吧!" );
所有权 所有权原则
Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
1 2 3 4 5 { let s = "hello" ;
字符串字面值&str
let s ="hello"创建,类型是&str,不可变,因为被硬编码到程序代码中
String类型
基于字符串字面量创建string类型:
1 2 3 4 5 let mut s = String ::from ("hello" );push_str (", world!" ); println! ("{}" , s);
有关所有权的讨论:
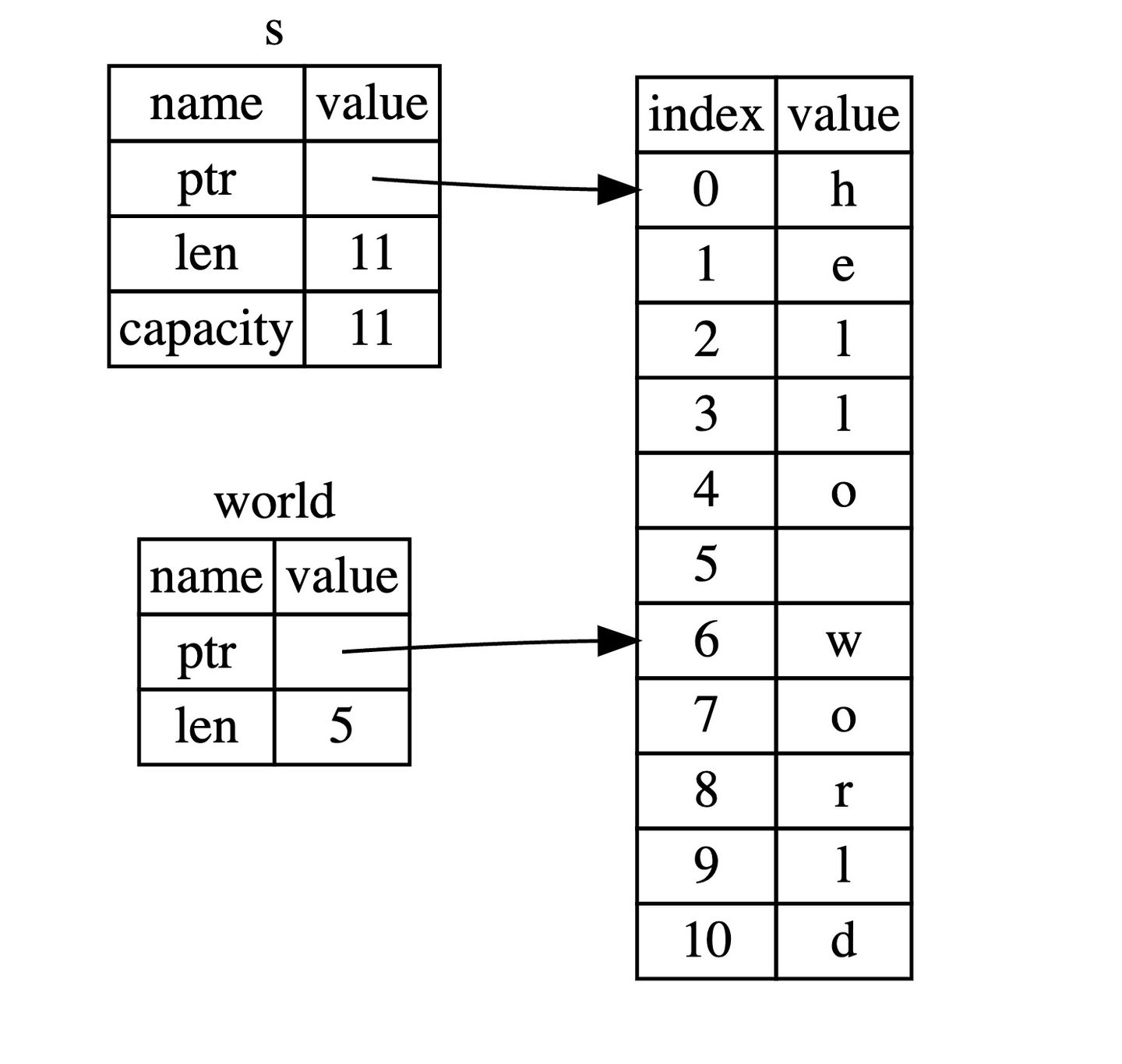
1 2 let s1 = String ::from ("hello" );let s2 = s1;
1 2 let s1 = String ::from ("hello" );let s2 = s1;
String 类型指向了一个堆 上的空间,这里存储着它的真实数据,下面对上面代码中的 let s2 = s1 分成两种情况讨论:
拷贝 String 和存储在堆上的字节数组 如果该语句是拷贝所有数据(深拷贝) ,那么无论是 String 本身还是底层的堆上数据,都会被全部拷贝,这对于性能而言会造成非常大的影响。
只拷贝 String 本身 这样的拷贝非常快,因为在 64 位机器上就拷贝了 8字节的指针、8字节的长度、8字节的容量(描述String的参数,而不是String所包含的具体内容,即移动(move) ),总计 24 字节,但是带来了新的问题,还记得我们之前提到的所有权规则吧?其中有一条就是:一个值只允许有一个所有者 ,而现在这个值(堆上的真实字符串数据)有了两个所有者:s1 和 s2。
为了避免变量离开作用域而二次释放内存,发生了所有权的转移:
1 2 3 4 5 6 7 8 let s1 = String ::from ("hello" );let s2 = s1;println! ("{}, world!" , s1);
通过上面的学习,我们更加理解了Rust的三个规则:
Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
因此,下面代码只涉及到引用,并不涉及所有权的转移:
1 2 3 4 5 fn main () {let x : &str = "hello, world" ;let y = x;println! ("{},{}" ,x,y);
深拷贝的实现:
1 2 let s1 = String ::from ("hello" );let s2 = s1.clone ();
像整型默认复制到栈上的类型有:
所有整数类型,比如 u32
布尔类型,bool,它的值是 true 和 false
所有浮点数类型,比如 f64
字符类型,char
元组,当且仅当其包含的类型也都是 Copy 的时候。比如,(i32, i32) 是 Copy 的,但 (i32, String) 就不是
不可变引用 &T ,例如转移所有权 中的最后一个例子,但是注意: 可变引用 &mut T 是不可以 Copy的
通过调用函数实现所有权的转移:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () {let s = String ::from ("hello" ); takes_ownership (s); let x = 5 ; makes_copy (x); fn takes_ownership (some_string: String ) { println! ("{}" , some_string);fn makes_copy (some_integer: i32 ) { println! ("{}" , some_integer);
同样,调用函数,函数返回值也会转移所有权:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 fn main () {let s1 = gives_ownership (); let s2 = String ::from ("hello" ); let s3 = takes_and_gives_back (s2); fn gives_ownership () -> String { let some_string = String ::from ("hello" ); fn takes_and_gives_back (a_string: String ) -> String {
引用和借用 引用和解引用
1 2 3 4 5 6 7 fn main () {let x = 5 ;let y = &x; assert_eq! (5 , x);assert_eq! (5 , *y);
不可变引用
1 2 3 4 5 6 7 8 9 10 11 fn main () {let s1 = String ::from ("hello" );let len = calculate_length (&s1);println! ("The length of '{}' is {}." , s1, len);fn calculate_length (s: &String ) -> usize {len ()
上面代码传入s1的引用,而不是转移s1的所有权
可变引用
上面的代码可以实现读取,而不能修改,要实现可变引用可以使用mut:
1 2 3 4 5 6 7 8 9 fn main () {let mut s = String ::from ("hello" );change (&mut s);fn change (some_string: &mut String ) {push_str (", world" );
注意:一个变量的可变引用只能有一个 ,防止数据竞争
补充数据竞争:
两个或更多的指针同时访问同一数据
至少有一个指针被用来写入数据
没有同步数据访问的机制
同样的,可变引用和不可用引用只能存在一个,防止脏读
悬垂引用(Dangling References)
即悬空指针
1 2 3 4 5 6 7 8 9 fn main () {let reference_to_nothing = dangle ();fn dangle () -> &String {let s = String ::from ("hello" );
当返回引用前,s就已经被释放了
解决办法:直接返回String
复合类型 切片 对于字符串而言,切片就是对 String 类型中某一部分的引用
1 2 3 4 let s = String ::from ("hello world" );let hello = &s[0 ..5 ];let world = &s[6 ..11 ];
与Python类似的切片方法:
1 2 3 4 5 6 7 8 9 10 11 let s = String ::from ("hello" );let len = s.len ();let slice = &s[4 ..len];let slice = &s[4 ..];let slice = &s[0 ..len];let slice = &s[..];
注意切片对中文支持可能存在问题,因为UTF-8为可变长编码 ,而中文字符占用3个字节,而切片是以字节 为单位的,所以就会存在问题。(补充:英文在UTF-8编码中采用与ASCII一样的编码方式,故只占用1字节)
字符串 正如上面所说,字符串是由字符组成的连续集合,而字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间。在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4)的可变长编码 ,这样有助于大幅降低字符串所占用的内存空间。故你最好不要对中文字符串进行切片。
str :str是一种不可变的字符串类型,也被称为字符串切片。它存储在程序的只读内存中,并且通常以引用的方式使用(即&str)。
&str: &str:&str是对str类型的引用,它是一种指向字符串切片的不可变引用。
String :String是一种可变的字符串类型,它是通过分配堆内存来存储字符串数据的。
&str转String:
1 2 String ::from ("hello,world" )"hello,world" .to_string ()
String转&str:
1 2 3 4 5 6 7 8 9 10 fn main () {let s = String ::from ("hello,world!" );say_hello (&s);say_hello (&s[..]);say_hello (s.as_str ());fn say_hello (s: &str ) {println! ("{}" ,s);
不要尝试对String索引,一是会报错,二是String采用UTF-8可变长编码,而且也不能在O(1)的复杂度下完成索引
字符串操作 追加Push
1 2 3 4 5 6 7 8 9 fn main () {let mut s = String ::from ("Hello " );push_str ("rust" );println! ("追加字符串 push_str() -> {}" , s);push ('!' );println! ("追加字符 push() -> {}" , s);
插入Insert
1 2 3 4 5 6 7 fn main () {let mut s = String ::from ("Hello rust!" );insert (5 , ',' );println! ("插入字符 insert() -> {}" , s);insert_str (6 , " I like" );println! ("插入字符串 insert_str() -> {}" , s);
同样如果是中文 字符你需要注意字符边界
替换Replace
replace
1 2 3 4 5 fn main () {let string_replace = String ::from ("I like rust. Learning rust is my favorite!" );let new_string_replace = string_replace.replace ("rust" , "RUST" );
replacen
1 2 3 4 5 fn main () {let string_replace = "I like rust. Learning rust is my favorite!" ;let new_string_replacen = string_replace.replacen ("rust" , "RUST" , 1 );
与replace不同,多加了一个替换个数的参数
replace_range
1 2 3 4 5 fn main () {let mut string_replace_range = String ::from ("I like rust!" );replace_range (7 ..8 , "R" );
需要指定范围,同样需要注意中文字符边界
1 2 3 4 5 6 7 fn main () {let mut string_replace_range = String ::from ("我喜欢RUST!" );replace_range (3 ..6 , "R" );4 ] string_replace_range = "我R欢RUST!"
删除Delete
pop
弹出最后一个UTF-8字符,包括中文
remove
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fn main () {let mut string_remove = String ::from ("测试remove方法" );println! ("string_remove 占 {} 个字节" ,size_of_val (string_remove.as_str ())remove (0 );
传的是一个起始索引位置,所以也要注意字符边界问题
truncate
删除字符串中从指定位置开始到结尾的全部字符
1 2 3 4 5 fn main () {let mut string_truncate = String ::from ("测试truncate" );truncate (3 );
传的是一个起始索引位置,所以也要注意字符边界问题
clear
清空字符串
1 2 3 4 5 fn main () {let mut string_clear = String ::from ("string clear" );clear ();
连接 (Concatenate)
使用 + 或者 += 连接字符串
要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add()add() 方法的第二个参数是一个引用的类型。因此我们在使用 +, 必须传递切片引用类型。不能直接传递 String 类型。+ 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰
1 2 3 4 5 6 7 8 9 10 fn main () {let string_append = String ::from ("hello " );let string_rust = String ::from ("rust" );let result = string_append + &string_rust;let mut result = result + "!" ; "!!!" ;println! ("连接字符串 + -> {}" , result);
add()方法定义:
1 fn add (self , s: &str ) -> String
1 2 3 4 5 6 7 8 9 fn main () {let s1 = String ::from ("hello," );let s2 = String ::from ("world!" );let s3 = s1 + &s2;assert_eq! (s3,"hello,world!" );
故字符串相加后s1被释放,不能再访问s1
但是由于add返回的是String,你可以接着继续相加操作:
1 2 3 4 5 6 let s1 = String ::from ("tic" );let s2 = String ::from ("tac" );let s3 = String ::from ("toe" );let s = s1 + "-" + &s2 + "-" + &s3;
使用 format! 连接字符串
1 2 3 4 5 6 fn main () {let s1 = "hello" ;let s2 = String ::from ("rust" );let s = format! ("{} {}!" , s1, s2);println! ("{}" , s);
字符串转义 与其它语言一样,使用 \ 转义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 fn main () {let byte_escape = "I'm writing \x52\x75\x73\x74!" ;println! ("What are you doing\x3F (\\x3F means ?) {}" , byte_escape);let unicode_codepoint = "\u{211D}" ;let character_name = "\"DOUBLE-STRUCK CAPITAL R\"" ;println! ("Unicode character {} (U+211D) is called {}" ,let long_string = "String literals can span multiple lines. The linebreak and indentation here ->\ <- can be escaped too!" ;println! ("{}" , long_string);'m writing Rust!211 D) is called "DOUBLE-STRUCK CAPITAL R" String literals-> <- can be escaped too!
避免字符串转义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 fn main () {println! ("{}" , "hello \\x52\\x75\\x73\\x74" );let raw_str = r"Escapes don't work here: \x3F \u{211D}" ;println! ("{}" , raw_str);let quotes = r#"And then I said: "There is no escape!""# ;println! ("{}" , quotes);let longer_delimiter = r###"A string with "# in it. And even "##!"### ;println! ("{}" , longer_delimiter);'t work here: \x3F \u{211 D}"There is no escape!" "# in it. And even " ##!
操作UTF-8字符串 正如上面介绍的utf-8为可变长编码,故不能直接索引遍历,可以使用下面的方法:
1 2 3 for c in "中国人" .chars () {println! ("{}" , c);
或者返回字节
1 2 3 for b in "中国人" .bytes () {println! ("{}" , b);
获取子串 holla中国人नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 可以考虑尝试下这个库:utf8_slice 。
元组 元组什么类型都可以放,复合类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 fn main () {let tup : (i32 , f64 , u8 ) = (500 , 6.4 , 1 );fn main () {let tup = (500 , 6.4 , 1 );let (x, y, z) = tup;println! ("The value of y is: {}" , y);fn main () {let x : (i32 , f64 , u8 ) = (500 , 6.4 , 1 );let five_hundred = x.0 ;let six_point_four = x.1 ;let one = x.2 ;
函数返回(经常使用元组):
1 2 3 4 5 fn calculate_length (s: String ) -> (String , usize ) {let length = s.len ();
结构体 定义:
1 2 3 4 5 6 struct User {bool ,String ,String ,u64 ,
创建实例:
1 2 3 4 5 6 let user1 = User {String ::from ("someone@example.com" ),String ::from ("someusername123" ),true ,1 ,
访问/修改:
1 user1.email = String ::from ("anotheremail@example.com" );
简化创建结构体函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 fn build_user (email: String , username: String ) -> User {true ,1 ,fn build_user (email: String , username: String ) -> User {true ,1 ,
结构体的更新方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 let user2 = User {String ::from ("another@example.com" ),let user2 = User {String ::from ("another@example.com" ),
但是使用旧的结构体更新,结构体内字段就会转移所有权,旧的字段就不能访问。但是其他字段还是可以正常访问。
结构体的内存排列如上,所以当发生了所有权的转移,并不会影响其他字段访问
元组结构体
无参数名,类似元组的方式
1 2 3 4 5 struct Color (i32 , i32 , i32 );struct Point (i32 , i32 , i32 );let black = Color (0 , 0 , 0 );let origin = Point (0 , 0 , 0 );
单元结构体
1 2 3 4 5 6 7 8 struct AlwaysEqual ;let subject = AlwaysEqual;impl SomeTrait for AlwaysEqual {
结构体避免使用引用类型
下面代码执行会报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct User {str ,str ,u64 ,bool ,fn main () {let user1 = User {"someone@example.com" ,"someusername123" ,true ,1 ,
枚举 栗子
1 2 3 4 5 6 enum PokerSuit {
使用枚举类型创建实例
1 2 let heart = PokerSuit::Hearts;let diamond = PokerSuit::Diamonds;
枚举可以关联数据类型到成员
1 2 3 4 5 6 7 8 9 10 11 enum PokerCard {Clubs (u8 ),Spades (u8 ),Diamonds (u8 ),Hearts (u8 ),fn main () {let c1 = PokerCard::Spades (5 );let c2 = PokerCard::Diamonds (13 );
数组 一些基本的操作1 2 3 4 5 6 7 8 9 let a = [1 , 2 , 3 , 4 , 5 ];let a : [i32 ; 5 ] = [1 , 2 , 3 , 4 , 5 ];let a = [3 ; 5 ];
数组的长度必须在编译期间已知
流程控制 if…else if…else…
1 2 3 4 5 if condition == true {else {
for
1 2 3 4 5 for i in 1 ..=5 {println! ("{}" , i);
1 2 3 for item in &container {
一般是取的集合的引用形式,不然for循环后由于所有权的转移,集合就无法使用了
1 2 3 for item in &mut collection {
想在循环中修改集合可以用上面这种形式
在for循环获取下标:
1 2 3 4 5 6 7 fn main () {let a = [4 , 3 , 2 , 1 ];for (i, v) in a.iter ().enumerate () {println! ("第{}个元素是{}" , i + 1 , v);
只控制循环次数:
continue,break
与c一样
while
1 2 3 4 5 6 7 let mut n = 0 ;while n <= 5 {println! ("{}!" , n);1 ;
loop
类似while true{},自己用break控制循环的结束条件
模式匹配 match匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 enum Direction {fn main () {let dire = Direction::South;match dire {println! ("East" ),println! ("South or North" );println! ("West" ),
可以归纳为下面的形式:
1 2 3 4 5 6 7 8 9 match target {1 => 表达式1 ,2 => {1 ;2 ;2 3
使用match表达式赋值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 enum IpAddr {fn main () {let ip1 = IpAddr::Ipv6;let ip_str = match ip1 {"127.0.0.1" ,"::1" ,println! ("{}" , ip_str);
感觉还挺常用?
模式绑定
从枚举类型中取绑定的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 enum Action {Say (String ),MoveTo (i32 , i32 ),ChangeColorRGB (u16 , u16 , u16 ),fn main () {let actions = [Say ("Hello Rust" .to_string ()),MoveTo (1 ,2 ),ChangeColorRGB (255 ,255 ,0 ),for action in actions {match action {Say (s) => {println! ("{}" , s);MoveTo (x, y) => {println! ("point from (0, 0) move to ({}, {})" , x, y);ChangeColorRGB (r, g, _) => {println! ("change color into '(r:{}, g:{}, b:0)', 'b' has been ignored" ,
if let 匹配
只匹配一个值用
例如:
1 2 3 if let Some (3 ) = v {println! ("three" );
matches!
例子如果想对一个枚举类型的数据过滤元素,可以使用下面的操作:
1 2 3 4 5 6 7 8 9 enum MyEnum {fn main () {let v = vec! [MyEnum::Foo,MyEnum::Bar,MyEnum::Foo];iter ().filter (|x| matches!(x, MyEnum::Foo));
while let
只要模式匹配就一直循环
1 2 3 4 5 6 7 8 9 10 11 12 13 let mut stack = Vec ::new ();push (1 );push (2 );push (3 );while let Some (top) = stack.pop () {println! ("{}" , top);
匹配序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 let x = 5 ;match x {1 ..=5 => println! ("one through five" ),println! ("something else" ),let x = 'c' ;match x {'a' ..='j' => println! ("early ASCII letter" ),'k' ..='z' => println! ("late ASCII letter" ),println! ("something else" ),
不定长数组解构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 let arr : &[u16 ] = &[114 , 514 ];if let [x, ..] = arr {assert_eq! (x, &114 );if let &[.., y] = arr {assert_eq! (y, 514 );let arr : &[u16 ] = &[];assert! (matches!(arr, [..]));assert! (!matches!(arr, [x, ..]));
匹配守卫
match分支后的额外if条件
1 2 3 4 5 6 7 let num = Some (4 );match num {Some (x) if x < 5 => println! ("less than five: {}" , x),Some (x) => println! ("{}" , x),None => (),
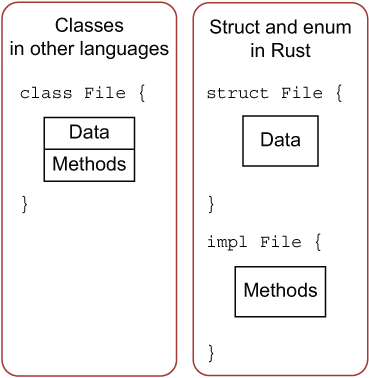
方法Method 用一幅图解释method
一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #[derive(Debug)] struct Rectangle {u32 ,u32 ,impl Rectangle {fn area (&self ) -> u32 {self .width * self .heightfn main () {let rect1 = Rectangle { width: 30 , height: 50 };println! ("The area of the rectangle is {} square pixels." ,area ()
self、&self 和 &mut self
self 表示 Rectangle 的所有权转移到该方法中,后面就用不了&self 表示该方法对 Rectangle 的不可变借用,用于读取&mut self 表示可变借用,用于修改
关联函数
类似构造函数,参数没有self的函数
1 2 3 4 5 impl Rectangle {fn new (w: u32 , h: u32 ) -> Rectangle {
泛型 声明
1 fn largest <T>(list: &[T]) -> T {
一个加法泛型函数
1 2 3 fn add <T: std::ops::Add<Output = T>>(a:T, b:T) -> T {
结构体中使用泛型
1 2 3 4 struct Point <T> {
枚举中使用泛型,最经典的Option
1 2 3 4 enum Option <T> {Some (T),None ,
方法中使用泛型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct Point <T> {impl <T> Point<T> {fn x (&self ) -> &T {self .xfn main () {let p = Point { x: 5 , y: 10 };println! ("p.x = {}" , p.x ());
Trait特征 有点类似于java的接口
特征定义:
1 2 3 pub trait Summary {fn summarize (&self ) -> String ;
特征的使用:
weibo和post对象都可以实现summarize这一特征
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 pub trait Summary {fn summarize (&self ) -> String ;pub struct Post {pub title: String , pub author: String , pub content: String , impl Summary for Post {fn summarize (&self ) -> String {format! ("文章{}, 作者是{}" , self .title, self .author)pub struct Weibo {pub username: String ,pub content: String ,impl Summary for Weibo {fn summarize (&self ) -> String {format! ("{}发表了微博{}" , self .username, self .content)fn main () {let post = Post {"Rust语言简介" .to_string (),"Sunface" .to_string (),"Rust棒极了!" .to_string (),let weibo = Weibo {"sunface" .to_string (),"好像微博没Tweet好用" .to_string (),println! ("{}" , post.summarize ());println! ("{}" , weibo.summarize ());
默认实现
1 2 3 4 5 pub trait Summary {fn summarize (&self ) -> String {String ::from ("(Read more...)" )
修改上面的实现代码,可以使用默认实现
1 2 3 4 5 6 7 impl Summary for Post {}impl Summary for Weibo {fn summarize (&self ) -> String {format! ("{}发表了微博{}" , self .username, self .content)
默认实现允许调用相同特征中的其他方法,哪怕这些方法没有默认实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 pub trait Tools {fn print1 (&self ) -> String ;fn print2 (&self ) -> String {String ::from ("(Read more...)" )pub struct Point {pub x: String ,pub y: String ,impl Tools for Point {fn print1 (&self ) -> String {String ::from ("TEST1" )fn main () {let point = Point {"1" .to_string (),"2" .to_string (),println! ("{}" , point.print2 ());
比如这个例子,实现了print1,但是可以使用print2的默认实现
使用特征作为函数参数
指的是任何实现了 Summary 特征的类型作为该函数的参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 pub trait Summary {fn summarize (&self ) -> String ;pub struct Post {pub title: String , pub author: String , pub content: String , impl Summary for Post {fn summarize (&self ) -> String {format! ("文章{}, 作者是{}" , self .title, self .author)pub struct Weibo {pub username: String ,pub content: String ,impl Summary for Weibo {fn summarize (&self ) -> String {format! ("{}发表了微博{}" , self .username, self .content)pub fn notify (item: &impl Summary ) {println! ("Breaking news! {}" , item.summarize ());fn main () {let post = Post {"Rust语言简介" .to_string (),"Sunface" .to_string (),"Rust棒极了!" .to_string (),let weibo = Weibo {"sunface" .to_string (),"好像微博没Tweet好用" .to_string (),notify (&weibo);
特征约束
语法糖模式(不强制限制两个item的类型要相同):1 pub fn notify (item1: &impl Summary , item2: &impl Summary ) {}
特征约束模式(两个item类型需要相同):
1 pub fn notify <T: Summary>(item1: &T, item2: &T) {}